Department of Information Management , Yuan Ze University
元智大學 資訊管理學系 第二十五屆專業實習

已完成進度
1061611 張唯潁
1061746 陳宛君
人體運動姿勢辨識及矯正比對分析系統之研究
從人體姿勢辨識就可大概了解需要有一個model去做辨識,而其來源則是透過影片或是電腦的攝像頭。最一開始我們要先以python來寫一個做影片的播放及執行的程式,接下來是作環境及模型的安裝,才能夠去偵測影片而去辨識影片中人物的姿勢。
我們所安裝的環境為ST-GCN,其中包括openpose要事先配置好,openpose可以說是一個套件或是一個model,安裝完後便可以去做基本的影像識別與偵測。
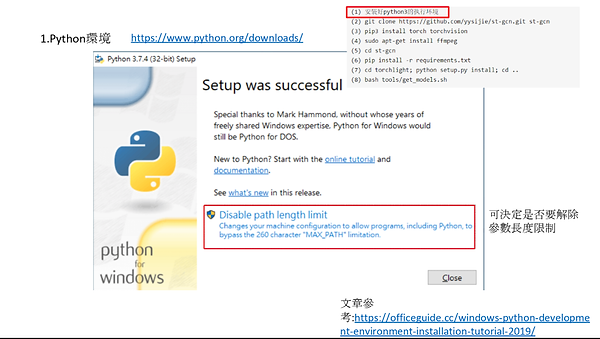
(一)在Windows上之作業內容
(1) 程式:
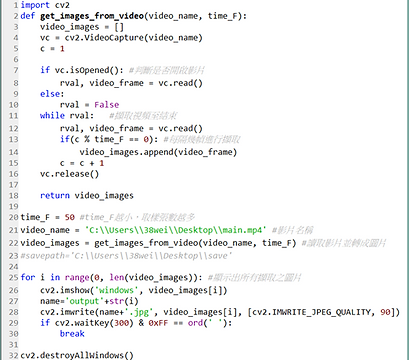
(2) 在Windows 10中Openpose的安裝:
-
先安裝學校的visual studio 2017用來作程式的執行。
-
從github抓取openpose套件(名稱為openpose-master),並且解壓縮,放入C槽。
-
從nvidia官網下載cuda,並且執行。
-
從nvidia官網下載與cuda版本相容的cudnn檔案。
-
cudnn檔案裡的資料夾會跟openpose-master中某些資料夾同名稱,將cudnn檔案丟入與他同檔名的openpose-master裡面覆蓋上去。
-
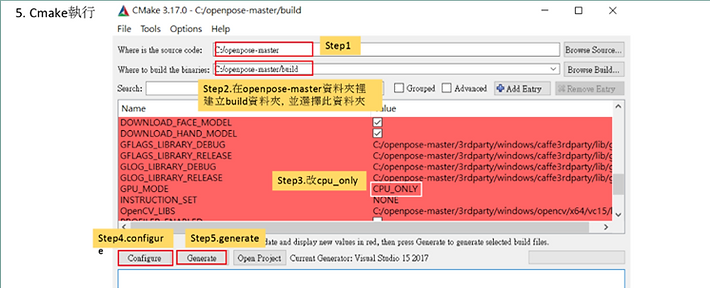
安裝cmake。
-
在openpose-master裡面新增一個build資料夾。
-
執行cmake,選擇build資料夾,中間有一項GPU-only改成CPU-only,執行generate進行配置,再執行configure進行編譯。
-
最後再build資料夾內會生成一個sln檔,透過visual studio 2017執行,就會出現openpose的影像偵測介面。
下方圖片為實作部分 :

(3) Windows系統上Openpose成果展示

由這些偵測結果畫面來看,可發現右上的數據幾乎都是以0.0 fps(幀率)的情形在運作,可能無法有效地實行接下來在ST-GCN的運動偵測。
(4) 在Windows 10中ST-GCN環境安裝
-
安裝Python環境+Anaconda
-
下載git bash軟體,在裡面使用git與bash指令下載之後會用到的ST-GCN source包
-
進入Anaconda Prompt
-
使用Pytorch官網指令下載Pytorch
-
執行pip install ffmpeg來安裝自動撥放影片的軟體
-
到ST-GCN之資料夾下,下載所需文件
-
再到ST-GCN資料夾下的torchlight資料夾下做python設定
-
進入git bash軟體中
-
最後在ST-GCN裡做模型的訓練
最後礙於模型的訓練無法完成,從網路上也找不到適合的模型資源,Windows的實作在此中斷。我們改為在Linux虛擬機上操作,並用之前的經驗一步一步建立環境,但是在openpose的架設上就停滯了,由於我們需要使用GPU圖形顯卡來執行,必須有驅動程式來驅動GPU與虛擬機之間的連結,但在此虛擬環境上總是沒辦法順利地安裝驅動程式,因此在虛擬機的實作亦無法進行。
(二)在Linux上之作業內容
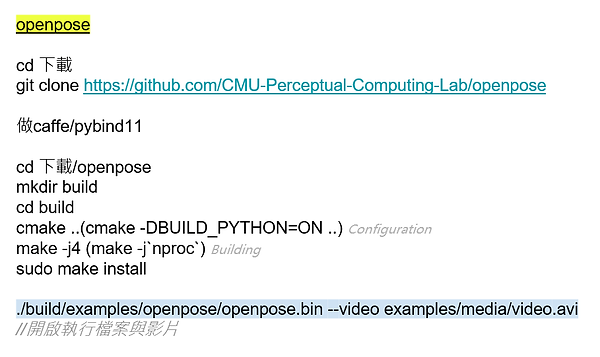
(1) 在Linux 18.04中Openpose的安裝
與在Windows安裝作法相似,差別在於Linux的所有步驟幾乎都是在終端機上完成的,包含下載檔案、安裝套件、檢查錯誤……等等,且Linux系統中並不使用Visual Studio來進行影片偵測,而是使用終端機執行指令來達到偵測的動作。
-
在Cuda的官網下載執行檔,用指令來執行檔案安裝Cuda,安裝過程中也包含了Nidia的驅動程式。
-
在cuDNN的官網下載與Cuda對應的cuDNN檔案,將解壓縮後的檔案放在/usr/local/cuda中相對應的資料夾中。
-
下載CMake安裝檔,用指令執行後進行編譯及安裝。
-
在Github下載Openpose的source文件,安裝caffe及pybind11在其中,並在openpose資料夾中建立build資料夾。
-
使用CMake及終端機進行build的編譯與生成檔案。
-
使用指令來執行影片中人體骨架的呈現。
-
各項重要之套件版本資訊:
作業系統:Ubuntu 18.04
CMake version : 3.18.1
OpenCV version: 4.4.0
CUDA version : 10.0
cuDNN version: 7.5.0
Python version: 3.6.9
Protobuf version: 3.12.3
-
各項套件的安裝指令內容:
(2) 在Linux 18.04中Openpose成果展示
以右上角的幀率來看,可以明顯的看出,在Linux系統中能夠運作得比較快速,且影片的播放也不會像在Window系統中不斷的停頓。
(3) 在Linux 18.04中ST-GCN環境安裝
這邊與在Windows上做的步驟大同小異,透過一樣的方法來安裝Anaconda、Pytorch、ffmpeg及ST-GCN的模型訓練。
(4) 在Linux 18.04中ST-GCN成果展示
(5) 在Linux 18.04中安裝所遇到的重大困難
經過我們從頭開始學習Linux系統後,發現Linux上有些不同於Windows的特點,例如:
-
文件之間是互相關聯的
透過指令生成軟連結並指定給其他文件,所以刪掉一部分有連結的文件可能會造成系統其他部分的損壞。
以下以Cudnn的安裝為示例,將libcudnn.so.7.5.0 文件連結到libcudnn.so.7,再將libcudnn.so.7 文件連結到libcudnn.so
若缺少連結或連結有物則出現以下圖片的情形
2. 安裝套件時需要進行編譯,且在指令中依格式加入所需參數
使用終端機來執行指令和軟體介面操作的差別在於,若需要改變編譯內容的項目,則需在指令內容加入參數去執行。
openpose的編譯為例:
如果希望以預設的值來編譯,就只需要輸入” cmake .. ”指令,但若需要建立Python,則使用” cmake -DBUILD_PYTHON=ON .. “的指令。
對我們來說,這些是Linux其中較不一樣的地方,因為Windows系統上對於大多數軟體的安裝與編譯,幾乎都是由圖形化介面來操作,非常的直覺。
我們因為這些特性不斷遇到重大困難,又或是對Linux不熟而陷入泥淖。以下舉例過程中遇到的重大問題與各種解決辦法,因為皆為非常重要的問題與過程,沒有這些問題也不會有這麼多的經驗與學習,因此特別記錄下來。
Ⅰ. 驅動程式
(a) 驅動程式無法成功安裝
通常是忘記關ubuntu的圖形介面,或是已安裝的第三方開源驅動nouveau阻擋。
解決方式:只要使用” sudo service lightdm stop ”關閉桌面服務,並按ctrl + alt + f1到達tty介面(純指令介面),再將nouveau加入系統黑名單及停用…等等一連串的設定。這時驅動就可以正常安裝,裝完則再開啟桌面服務就可以了。
但有時則會因為不知名原因(完全沒顯示任何error訊息)而無法安裝,因此用系統建議的”apt-get install”指令直接執行,或是使用Nvidia官網下載的驅動程式檔案,也試過用Cuda安裝中自帶的驅動程式來裝,種種嘗試都是經驗的一部份。
(a) 驅動程式會自動跑掉
驅動程式的部分成功後,接著安裝不同的所需套件,但是經常發現驅動程式又呈現抓不到的情形,因此每次跑掉就重裝的動作是其中一部分艱辛過程,而且有時重裝的錯誤訊息會不同,就算有多次安裝經驗,還是不一定次次順利,也曾經導致螢幕黑屏過,最後才決定要去認真深入地解決此問題。
解決方式:關於這部分的問題其實花了很多心力去找,網路上一共找了3個辦法,第三個辦法才成功。這個辦法是用DKMS去更新內核的版本,而主要原因則是因為內核與驅動的版本並不一致。
Ⅱ. Cmake 安裝完有出現版本資訊,但安裝過程卻有出錯
因為後面的編譯不斷地缺少東西,覺得很有可能是這邊的問題,因此解決辦法找了數周。
問題:指令執行過程中顯示缺少被參考到libGL.so文件
解決辦法:主要辦法還是自己研究終端機出現的訊息,因為網路上幾乎找不到關於這種問題的資訊。因此到libGL.so文件中查看,檢查到其中參考連結已損壞。而在安裝libgl1及libglvnd-dev套件時,會自動新增libGL.so檔到home位置,後來發現此位置的libGL.so檔有參考到aarch64-linux-gnu此資料夾中檔案,因此下載gcc-aarch64-linux-gnu取得此資料夾,但其中卻沒有需要被libGL.so參考到的libGL.so.1.0.0檔案,因此嘗試安裝相關套件,並且把libGL.so.1.0.0複製到aarch64-linux-gnu資料夾裡,最後cmake編譯就因此成功了。
Ⅲ. 用CMake編譯Openpose上的問題
(a) 編譯器抓不到Cudnn
由於一直無法抓到已裝好的Cudnn,導致後續的編譯經常失敗,驅動程式、Cuda、CMake、Cudnn的版本必須相符合才能編譯成功,且有時候成功了,但是隔天就會失敗,若需要再重新編譯,則會發現抓不到Cudnn為我們帶來很大的麻煩。因此慢慢尋找其問題之原因所在,詢問有相關經驗的人後,試著將Cuda及Cudnn降版本,最後以cuda 10.0版本與cudnn 7.5.0版本來解決了。
(b) Openpose編譯後的example資料夾沒有出現
我們認為這是個神奇的問題,網路上似乎也沒有人出現過這種情形。
解決方式:某天發現很多文章中都建議大家不要使用CMake介面做編譯,突然就靈機一閃,用CMake介面操作是根本就是Windows的做法,因此決定都用指令去操作,結果下指令編譯完,我們需要的example資料夾就出現了。
(c) Openpose編譯完了卻無法偵測出人體骨架
當我們將openpose環境的前置套件都安裝好後,卻發現能用openpose正常撥放影片,卻沒有在畫面中呈現人體骨架,且無顯示可參考的錯誤訊息
解決方式:更改OpenCV版本後雖無法播放影片,但我們研究錯誤訊息並上網搜尋,發現OpenCV需先在有安裝ffmpeg的環境下進行編譯,因此卸載OpenCV,安裝好ffmpeg後再進行OpenCV編譯安裝,最後測試Openpose的影片偵測就呈現骨架了。
在安裝時常常遇到問題,其中有版本不相容、不確定意思的Error、安裝順序與是否成功有一定的關係等等的問題,常常做到很後面還是最後一直出錯,就只能夠再次解除安裝重新開始,因此是一項大工程,完成所花費的時間有好幾個月。
Ⅳ. Openpose編譯完了卻無法偵測出人體骨架
當我們將openpose環境的前置套件都安裝好後,卻發現能用openpose正常撥放影片,卻沒有在畫面中呈現人體骨架,且無顯示可參考的錯誤訊息
解決方式:更改OpenCV版本後雖無法播放影片,但我們研究錯誤訊息並上網搜尋,發現OpenCV需先在有安裝ffmpeg的環境下進行編譯,因此卸載OpenCV,安裝好ffmpeg後再進行OpenCV編譯安裝,最後測試Openpose的影片偵測就呈現骨架了。
在安裝時常常遇到問題,其中有版本不相容、不確定意思的Error、安裝順序與是否成功有一定的關係等等的問題,常常做到很後面還是最後一直出錯,就只能夠再次解除安裝重新開始,因此是一項大工程,完成所花費的時間非常久。
(6) Openpose生成數據之處理
- openpose生成的骨架數據
當一個影片經過Openpose運算後,會產生多個Frame的json資料,大約每秒生成30個Frame。








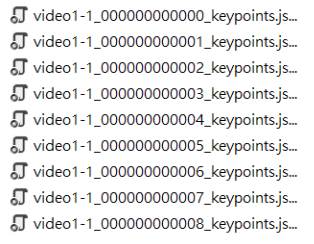
以下是其中一個Frame的json數據內容,圖中第二行為Openpose的骨架訊息,用前三個數字為例,706.808為x座標,129.872為y座標,0.883361為confidence score。

2. 轉成Excel檔
由於每一份數據皆有有規律,因此透過python來將這些有規律的資�料轉成exel檔,如下圖所示
3.取用資料

(7) LSTM model的訓練
程式環境:利用Google的Colaboratory環境去建置LSTM model
1. Initial:讀取雲端所有的影片數據
3.取用資料

2. 設定model的Input與Output
-
Data_x = 將所有(包含標準影片及其他影片)數據以陣列形式作為Input
-
Data_y = 將每個影片標註為1或0,作為最後的Output
-
若是騎士二式,標註1
-
若不是騎士二式,標註0

由這些偵測結果畫面來看,可發現右上的數據幾乎都是以0.0 fps(幀率)的情形在運作,可能無法有效地實行接下來在ST-GCN的運動偵測。
(4) 在Windows 10中ST-GCN環境安裝
-
安裝Python環境+Anaconda
-
下載git bash軟體,在裡面使用git與bash指令下載之後會用到的ST-GCN source包
-
進入Anaconda Prompt
-
使用Pytorch官網指令下載Pytorch
-
執行pip install ffmpeg來安裝自動撥放影片的軟體
-
到ST-GCN之資料夾下,下載所需文件
-
再到ST-GCN資料夾下的torchlight資料夾下做python設定
-
進入git bash軟體中
-
最後在ST-GCN裡做模型的訓練
最後礙於模型的訓練無法完成,從網路上也找不到適合的模型資源,Windows的實作在此中斷。我們改為在Linux虛擬機上操作,並用之前的經驗一步一步建立環境,但是在openpose的架設上就停滯了,由於我們需要使用GPU圖形顯卡來執行,必須有驅動程式來驅動GPU與虛擬機之間的連結,但在此虛擬環境上總是沒辦法順利地安裝驅動程式,因此在虛擬機的實作亦無法進行。
(二)在Linux上之作業內容
(1) 在Linux 18.04中Openpose的安裝
與在Windows安裝作法相似,差別在於Linux的所有步驟幾乎都是在終端機上完成的,包含下載檔案、安裝套件、檢查錯誤……等等,且Linux系統中並不使用Visual Studio來進行影片偵測,而是使用終端機執行指令來達到偵測的動作。
-
在Cuda的官網下載執行檔,用指令來執行檔案安裝Cuda,安裝過程中也包含了Nidia的驅動程式。
-
在cuDNN的官網下載與Cuda對應的cuDNN檔案,將解壓縮後的檔案放在/usr/local/cuda中相對應的資料夾中。
-
下載CMake安裝檔,用指令執行後進行編譯及安裝。
-
在Github下載Openpose的source文件,安裝caffe及pybind11在其中,並在openpose資料夾中建立build資料夾。
-
使用CMake及終端機進行build的編譯與生成檔案。
-
使用指令來執行影片中人體骨架的呈現。
-
各項重要之套件版本資訊:
作業系統:Ubuntu 18.04
CMake version : 3.18.1
OpenCV version: 4.4.0
CUDA version : 10.0
cuDNN version: 7.5.0
Python version: 3.6.9
Protobuf version: 3.12.3
-
各項套件的安裝指令內容:
(2) 在Linux 18.04中Openpose成果展示
以右上角的幀率來看,可以明顯的看出,在Linux系統中能夠運作得比較快速,且影片的播放也不會像在Window系統中不斷的停頓。
(3) 在Linux 18.04中ST-GCN環境安裝
這邊與在Windows上做的步驟大同小異,透過一樣的方法來安裝Anaconda、Pytorch、ffmpeg及ST-GCN的模型訓練。
(4) 在Linux 18.04中ST-GCN成果展示
(5) 在Linux 18.04中安裝所遇到的重大困難
經過我們從頭開始學習Linux系統後,發現Linux上有些不同於Windows的特點,例如:
-
文件之間是互相關聯的
透過指令生成軟連結並指定給其他文件,所以刪掉一部分有連結的文件可能會造成系統其他部分的損壞。
以下以Cudnn的安裝為示例,將libcudnn.so.7.5.0 文件連結到libcudnn.so.7,再將libcudnn.so.7 文件連結到libcudnn.so
若缺少連結或連結有物則出現以下圖片的情形
2. 安裝套件時需要進行編譯,且在指令中依格式加入所需參數
使用終端機來執行指令和軟體介面操作的差別在於,若需要改變編譯內容的項目,則需在指令內容加入參數去執行。
openpose的編譯為例:
如果希望以預設的值來編譯,就只需要輸入” cmake .. ”指令,但若需要建立Python,則使用” cmake -DBUILD_PYTHON=ON .. “的指令。
對我們來說,這些是Linux其中較不一樣的地方,因為Windows系統上對於大多數軟體的安裝與編譯,幾乎都是由圖形化介面來操作,非常的直覺。
我們因為這些特性不斷遇到重大困難,又或是對Linux不熟而陷入泥淖。以下舉例過程中遇到的重大問題與各種解決辦法,因為皆為非常重要的問題與過程,沒有這些問題也不會有這麼多的經驗與學習,因此特別記錄下來。
Ⅰ. 驅動程式
(a) 驅動程式無法成功安裝
通常是忘記關ubuntu的圖形介面,或是已安裝的第三方開源驅動nouveau阻擋。
解決方式:只要使用” sudo service lightdm stop ”關閉桌面服務,並按ctrl + alt + f1到達tty介面(純指令介面),再將nouveau加入系統黑名單及停用…等等一連串的設定。這時驅動就可以正常安裝,裝完則再開啟桌面服務就可以了。
但有時則會因為不知名原因(完全沒顯示任何error訊息)而無法安裝,因此用系統建議的”apt-get install”指令直接執行,或是使用Nvidia官網下載的驅動程式檔案,也試過用Cuda安裝中自帶的驅動程式來裝,種種嘗試都是經驗的一部份。
(a) 驅動程式會自動跑掉
驅動程式的部分成功後,接著安裝不同的所需套件,但是經常發現驅動程式又呈現抓不到的情形,因此每次跑掉就重裝的動作是其中一部分艱辛過程,而且有時重裝的錯誤訊息會不同,就算有多次安裝經驗,還是不一定次次順利,也曾經導致螢幕黑屏過,最後才決定要去認真深入地解決此問題。
解決方式:關於這部分的問題其實花了很多心力去找,網路上一共找了3個辦法,第三個辦法才成功。這個辦法是用DKMS去更新內核的版本,而主要原因則是因為內核與驅動的版本並不一致。
Ⅱ. Cmake 安裝完有出現版本資訊,但安裝過程卻有出錯
因為後面的編譯不斷地缺少東西,覺得很有可能是這邊的問題,因此解決辦法找了數周。
問題:指令執行過程中顯示缺少被參考到libGL.so文件
解決辦法:主要辦法還是自己研究終端機出現的訊息,因為網路上幾乎找不到關於這種問題的資訊。因此到libGL.so文件中查看,檢查到其中參考連結已損壞。而在安裝libgl1及libglvnd-dev套件時,會自動新增libGL.so檔到home位置,後來發現此位置的libGL.so檔有參考到aarch64-linux-gnu此資料夾中檔案,因此下載gcc-aarch64-linux-gnu取得此資料夾,但其中卻沒有需要被libGL.so參考到的libGL.so.1.0.0檔案,因此嘗試安裝相關套件,並且把libGL.so.1.0.0複製到aarch64-linux-gnu資料夾裡,最後cmake編譯就因此成功了。
Ⅲ. 用CMake編譯Openpose上的問題
(a) 編譯器抓不到Cudnn
由於一直無法抓到已裝好的Cudnn,導致後續的編譯經常失敗,驅動程式、Cuda、CMake、Cudnn的版本必須相符合才能編譯成功,且有時候成功了,但是隔天就會失敗,若需要再重新編譯,則會發現抓不到Cudnn為我們帶來很大的麻煩。因此慢慢尋找其問題之原因所在,詢問有相關經驗的人後,試著將Cuda及Cudnn降版本,最後以cuda 10.0版本與cudnn 7.5.0版本來解決了。
(b) Openpose編譯後的example資料夾沒有出現
我們認為這是個神奇的問題,網路上似乎也沒有人出現過這種情形。
解決方式:某天發現很多文章中都建議大家不要使用CMake介面做編譯,突然就靈機一閃,用CMake介面操作是根本就是Windows的做法,因此決定都用指令去操作,結果下指令編譯完,我們需要的example資料夾就出現了。
(c) Openpose編譯完了卻無法偵測出人體骨架
當我們將openpose環境的前置套件都安裝好後,卻發現能用openpose正常撥放影片,卻沒有在畫面中呈現人體骨架,且無顯示可參考的錯誤訊息
解決方式:更改OpenCV版本後雖無法播放影片,但我們研究錯誤訊息並上網搜尋,發現OpenCV需先在有安裝ffmpeg的環境下進行編譯,因此卸載OpenCV,安裝好ffmpeg後再進行OpenCV編譯安裝,最後測試Openpose的影片偵測就呈現骨架了。
在安裝時常常遇到問題,其中有版本不相容、不確定意思的Error、安裝順序與是否成功有一定的關係等等的問題,常常做到很後面還是最後一直出錯,就只能夠再次解除安裝重新開始,因此是一項大工程,完成所花費的時間有好幾個月。
Ⅳ. Openpose編譯完了卻無法偵測出人體骨架
當我們將openpose環境的前置套件都安裝好後,卻發現能用openpose正常撥放影片,卻沒有在畫面中呈現人體骨架,且無顯示可參考的錯誤訊息
解決方式:更改OpenCV版本後雖無法播放影片,但我們研究錯誤訊息並上網搜尋,發現OpenCV需先在有安裝ffmpeg的環境下進行編譯,因此卸載OpenCV,安裝好ffmpeg後再進行OpenCV編譯安裝,最後測試Openpose的影片偵測就呈現骨架了。
在安裝時常常遇到問題,其中有版本不相容、不確定意思的Error、安裝順序與是否成功有一定的關係等等的問題,常常做到很後面還是最後一直出錯,就只能夠再次解除安裝重新開始,因此是一項大工程,完成所花費的時間非常久。
(6) Openpose生成數據之處理
- openpose生成的骨架數據
當一個影片經過Openpose運算後,會產生多個Frame的json資料,大約每秒生成30個Frame。
以下是其中一個Frame的json數據內容,圖中第二行為Openpose的骨架訊息,用前三個數字為例,706.808為x座標,129.872為y座標,0.883361為confidence score。
2. 轉成Excel檔
由於每一份數據皆有有規律,因此透過python來將這些有規律的資料轉成exel檔,如下圖所示
3.取用資料
(7) LSTM model的訓練
程式環境:利用Google的Colaboratory環境去建置LSTM model
1. Initial:讀取雲端所有的影片數據
3.取用資料
2. 設定model的Input與Output
-
Data_x = 將所有(包含標準影片及其他影片)數據以陣列形式作為Input
-
Data_y = 將每個影片標註為1或0,作為最後的Output
-
若是騎士二式,標註1
-
若不是騎士二式,標註0

3. 建立model
-
設定好model要接收的Input與Output的樣子
-
再設置model的其他參數(optimizer、loss function)

4. 訓練model
-
將model的Input與Output位置放入前面定義過的data_x、data_y
-
設定每次拿取的資料量
-
將model重複訓練多次,使model的學習效果達到一定程度

5. 測試model訓練後結果
-
拿一份未經訓練的三角式影片數據去做測試

測試結果:Output為0,此模型判斷影片2-10的動作不是標準的騎士二式。